In saezlab/decoupleR: decoupleR: Ensemble of computational methods to infer biological activities from omics data
knitr::opts_chunk$set(
collapse = TRUE,
comment = "#>"
)
scRNA-seq yield many molecular readouts that are hard to interpret by
themselves. One way of summarizing this information is by inferring pathway
activities from prior knowledge.
In this notebook we showcase how to use decoupleR for pathway activity
inference with a down-sampled PBMCs 10X data-set. The data consists of 160
PBMCs from a Healthy Donor. The original data is freely available from 10x Genomics
here
from this webpage.
Loading packages
First, we need to load the relevant packages, Seurat to handle scRNA-seq data
and decoupleR to use statistical methods.
## We load the required packages
library(Seurat)
library(decoupleR)
# Only needed for data handling and plotting
library(dplyr)
library(tibble)
library(tidyr)
library(patchwork)
library(ggplot2)
library(pheatmap)
Loading the data-set
Here we used a down-sampled version of the data used in the Seurat
vignette.
We can open the data like this:
inputs_dir <- system.file("extdata", package = "decoupleR")
data <- readRDS(file.path(inputs_dir, "sc_data.rds"))
We can observe that we have different cell types:
p <- Seurat::DimPlot(data,
reduction = "umap",
label = TRUE,
pt.size = 0.5) +
Seurat::NoLegend()
p
PROGENy model
PROGENy is a comprehensive resource containing a curated collection of pathways and their target genes, with weights for each interaction.
For this example we will use the human weights (other organisms are available) and we will use the top 500 responsive genes ranked by p-value. Here is a brief description of each pathway:
- Androgen: involved in the growth and development of the male reproductive organs.
- EGFR: regulates growth, survival, migration, apoptosis, proliferation, and differentiation in mammalian cells
- Estrogen: promotes the growth and development of the female reproductive organs.
- Hypoxia: promotes angiogenesis and metabolic reprogramming when O2 levels are low.
- JAK-STAT: involved in immunity, cell division, cell death, and tumor formation.
- MAPK: integrates external signals and promotes cell growth and proliferation.
- NFkB: regulates immune response, cytokine production and cell survival.
- p53: regulates cell cycle, apoptosis, DNA repair and tumor suppression.
- PI3K: promotes growth and proliferation.
- TGFb: involved in development, homeostasis, and repair of most tissues.
- TNFa: mediates haematopoiesis, immune surveillance, tumour regression and protection from infection.
- Trail: induces apoptosis.
- VEGF: mediates angiogenesis, vascular permeability, and cell migration.
- WNT: regulates organ morphogenesis during development and tissue repair.
To access it we can use decoupleR:
net <- decoupleR::get_progeny(organism = 'human', top = 500)
net
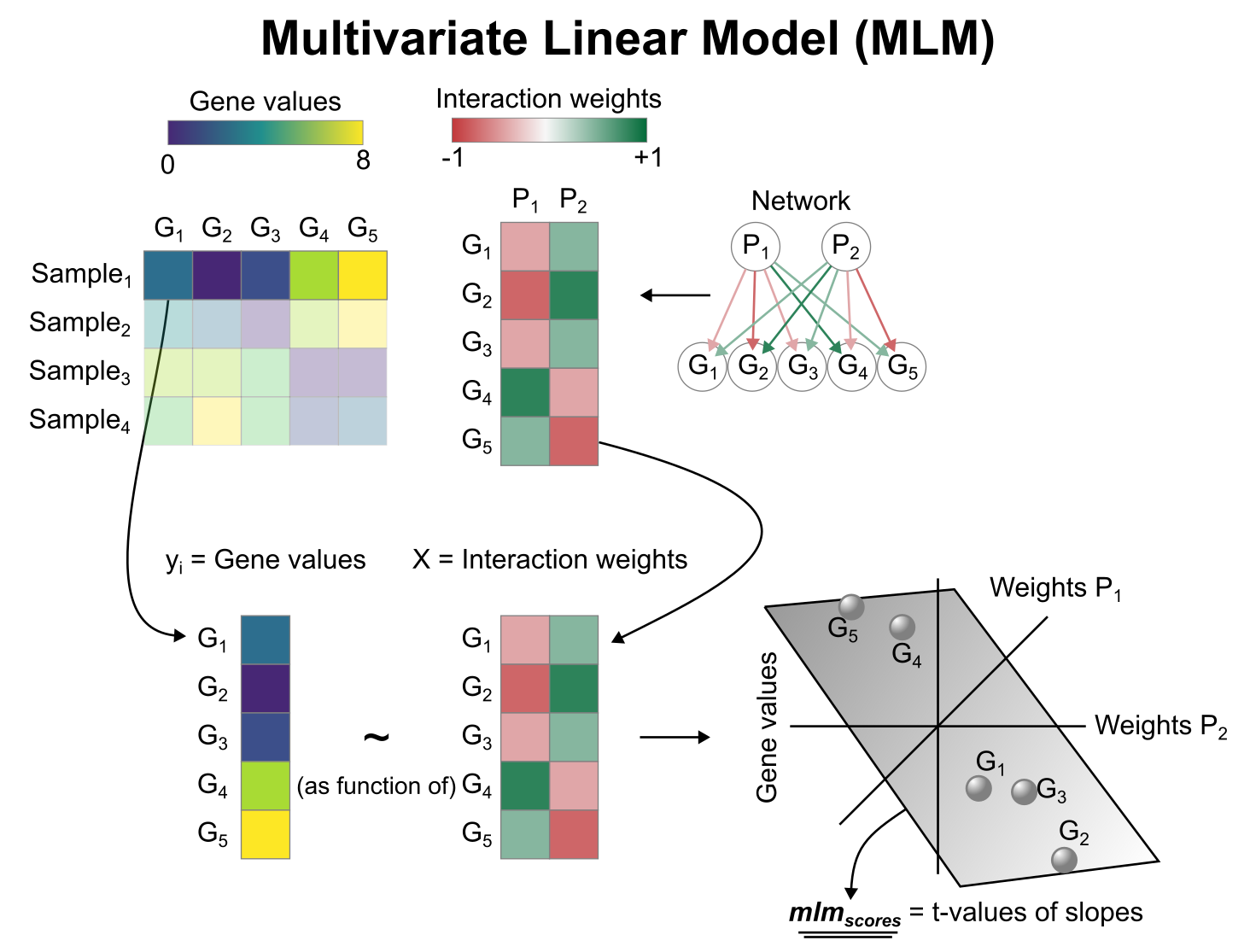
Activity inference with Multivariate Linear Model (MLM)
To infer pathway enrichment scores we will run the Multivariate Linear Model (mlm) method. For each sample in our dataset (mat), it fits a linear model that predicts the observed gene expression based on all pathways' Pathway-Gene interactions weights.
Once fitted, the obtained t-values of the slopes are the scores. If it is positive, we interpret that the pathway is active and if it is negative we interpret that it is inactive.
To run decoupleR methods, we need an input matrix (mat), an input prior
knowledge network/resource (net), and the name of the columns of net that we
want to use.
# Extract the normalized log-transformed counts
mat <- as.matrix(data@assays$RNA@data)
# Run mlm
acts <- decoupleR::run_mlm(mat = mat,
net = net,
.source = 'source',
.target = 'target',
.mor = 'weight',
minsize = 5)
acts
Visualization
From the obtained results, we will select the ulm activities and store
them in our object as a new assay called pathwaysmlm:
# Extract mlm and store it in pathwaysmlm in data
data[['pathwaysmlm']] <- acts %>%
tidyr::pivot_wider(id_cols = 'source',
names_from = 'condition',
values_from = 'score') %>%
tibble::column_to_rownames(var = 'source') %>%
Seurat::CreateAssayObject(.)
# Change assay
Seurat::DefaultAssay(object = data) <- "pathwaysmlm"
# Scale the data
data <- Seurat::ScaleData(data)
data@assays$pathwaysmlm@data <- data@assays$pathwaysmlm@scale.data
This new assay can be used to plot activities. Here we visualize the Trail
pathway, associated with apoptosis, which seems that in B and NK cells is more
active.
p1 <- Seurat::DimPlot(data,
reduction = "umap",
label = TRUE,
pt.size = 0.5) +
Seurat::NoLegend() +
ggplot2::ggtitle('Cell types')
colors <- rev(RColorBrewer::brewer.pal(n = 11, name = "RdBu")[c(2, 10)])
p2 <- Seurat::FeaturePlot(data, features = c("Trail")) +
ggplot2::scale_colour_gradient2(low = colors[1], mid = 'white', high = colors[2]) +
ggplot2::ggtitle('Trail activity')
p <- p1 | p2
p
Exploration
We can also see what is the mean activity per group across pathways:
# Extract activities from object as a long dataframe
df <- t(as.matrix(data@assays$pathwaysmlm@data)) %>%
as.data.frame() %>%
dplyr::mutate(cluster = Seurat::Idents(data)) %>%
tidyr::pivot_longer(cols = -cluster,
names_to = "source",
values_to = "score") %>%
dplyr::group_by(cluster, source) %>%
dplyr::summarise(mean = mean(score))
# Transform to wide matrix
top_acts_mat <- df %>%
tidyr::pivot_wider(id_cols = 'cluster',
names_from = 'source',
values_from = 'mean') %>%
tibble::column_to_rownames(var = 'cluster') %>%
as.matrix()
# Color scale
colors <- rev(RColorBrewer::brewer.pal(n = 11, name = "RdBu"))
colors.use <- grDevices::colorRampPalette(colors = colors)(100)
my_breaks <- c(seq(-1.25, 0, length.out = ceiling(100 / 2) + 1),
seq(0.05, 1.25, length.out = floor(100 / 2)))
# Plot
pheatmap::pheatmap(mat = top_acts_mat,
color = colors.use,
border_color = "white",
breaks = my_breaks,
cellwidth = 20,
cellheight = 20,
treeheight_row = 20,
treeheight_col = 20)
In this specific example, we can observe that Trail is more active in B and NK
cells.
Session information
options(width = 120)
sessioninfo::session_info()
saezlab/decoupleR documentation built on Oct. 21, 2024, 8:47 a.m.
R Package Documentation
Browse R Packages
We want your feedback!
Note that we can't provide technical support on individual packages. You should contact the package authors for that.
knitr::opts_chunk$set( collapse = TRUE, comment = "#>" )
scRNA-seq yield many molecular readouts that are hard to interpret by themselves. One way of summarizing this information is by inferring pathway activities from prior knowledge.
In this notebook we showcase how to use decoupleR for pathway activity
inference with a down-sampled PBMCs 10X data-set. The data consists of 160
PBMCs from a Healthy Donor. The original data is freely available from 10x Genomics
here
from this webpage.
Loading packages
First, we need to load the relevant packages, Seurat to handle scRNA-seq data
and decoupleR to use statistical methods.
## We load the required packages library(Seurat) library(decoupleR) # Only needed for data handling and plotting library(dplyr) library(tibble) library(tidyr) library(patchwork) library(ggplot2) library(pheatmap)
Loading the data-set
Here we used a down-sampled version of the data used in the Seurat
vignette.
We can open the data like this:
inputs_dir <- system.file("extdata", package = "decoupleR") data <- readRDS(file.path(inputs_dir, "sc_data.rds"))
We can observe that we have different cell types:
p <- Seurat::DimPlot(data, reduction = "umap", label = TRUE, pt.size = 0.5) + Seurat::NoLegend() p
PROGENy model
PROGENy is a comprehensive resource containing a curated collection of pathways and their target genes, with weights for each interaction. For this example we will use the human weights (other organisms are available) and we will use the top 500 responsive genes ranked by p-value. Here is a brief description of each pathway:
- Androgen: involved in the growth and development of the male reproductive organs.
- EGFR: regulates growth, survival, migration, apoptosis, proliferation, and differentiation in mammalian cells
- Estrogen: promotes the growth and development of the female reproductive organs.
- Hypoxia: promotes angiogenesis and metabolic reprogramming when O2 levels are low.
- JAK-STAT: involved in immunity, cell division, cell death, and tumor formation.
- MAPK: integrates external signals and promotes cell growth and proliferation.
- NFkB: regulates immune response, cytokine production and cell survival.
- p53: regulates cell cycle, apoptosis, DNA repair and tumor suppression.
- PI3K: promotes growth and proliferation.
- TGFb: involved in development, homeostasis, and repair of most tissues.
- TNFa: mediates haematopoiesis, immune surveillance, tumour regression and protection from infection.
- Trail: induces apoptosis.
- VEGF: mediates angiogenesis, vascular permeability, and cell migration.
- WNT: regulates organ morphogenesis during development and tissue repair.
To access it we can use decoupleR:
net <- decoupleR::get_progeny(organism = 'human', top = 500) net
Activity inference with Multivariate Linear Model (MLM)
To infer pathway enrichment scores we will run the Multivariate Linear Model (mlm) method. For each sample in our dataset (mat), it fits a linear model that predicts the observed gene expression based on all pathways' Pathway-Gene interactions weights.
Once fitted, the obtained t-values of the slopes are the scores. If it is positive, we interpret that the pathway is active and if it is negative we interpret that it is inactive.
To run decoupleR methods, we need an input matrix (mat), an input prior
knowledge network/resource (net), and the name of the columns of net that we
want to use.
# Extract the normalized log-transformed counts mat <- as.matrix(data@assays$RNA@data) # Run mlm acts <- decoupleR::run_mlm(mat = mat, net = net, .source = 'source', .target = 'target', .mor = 'weight', minsize = 5) acts
Visualization
From the obtained results, we will select the ulm activities and store
them in our object as a new assay called pathwaysmlm:
# Extract mlm and store it in pathwaysmlm in data data[['pathwaysmlm']] <- acts %>% tidyr::pivot_wider(id_cols = 'source', names_from = 'condition', values_from = 'score') %>% tibble::column_to_rownames(var = 'source') %>% Seurat::CreateAssayObject(.) # Change assay Seurat::DefaultAssay(object = data) <- "pathwaysmlm" # Scale the data data <- Seurat::ScaleData(data) data@assays$pathwaysmlm@data <- data@assays$pathwaysmlm@scale.data
This new assay can be used to plot activities. Here we visualize the Trail pathway, associated with apoptosis, which seems that in B and NK cells is more active.
p1 <- Seurat::DimPlot(data, reduction = "umap", label = TRUE, pt.size = 0.5) + Seurat::NoLegend() + ggplot2::ggtitle('Cell types') colors <- rev(RColorBrewer::brewer.pal(n = 11, name = "RdBu")[c(2, 10)]) p2 <- Seurat::FeaturePlot(data, features = c("Trail")) + ggplot2::scale_colour_gradient2(low = colors[1], mid = 'white', high = colors[2]) + ggplot2::ggtitle('Trail activity') p <- p1 | p2 p
Exploration
We can also see what is the mean activity per group across pathways:
# Extract activities from object as a long dataframe df <- t(as.matrix(data@assays$pathwaysmlm@data)) %>% as.data.frame() %>% dplyr::mutate(cluster = Seurat::Idents(data)) %>% tidyr::pivot_longer(cols = -cluster, names_to = "source", values_to = "score") %>% dplyr::group_by(cluster, source) %>% dplyr::summarise(mean = mean(score)) # Transform to wide matrix top_acts_mat <- df %>% tidyr::pivot_wider(id_cols = 'cluster', names_from = 'source', values_from = 'mean') %>% tibble::column_to_rownames(var = 'cluster') %>% as.matrix() # Color scale colors <- rev(RColorBrewer::brewer.pal(n = 11, name = "RdBu")) colors.use <- grDevices::colorRampPalette(colors = colors)(100) my_breaks <- c(seq(-1.25, 0, length.out = ceiling(100 / 2) + 1), seq(0.05, 1.25, length.out = floor(100 / 2))) # Plot pheatmap::pheatmap(mat = top_acts_mat, color = colors.use, border_color = "white", breaks = my_breaks, cellwidth = 20, cellheight = 20, treeheight_row = 20, treeheight_col = 20)
In this specific example, we can observe that Trail is more active in B and NK cells.
Session information
options(width = 120) sessioninfo::session_info()
R Package Documentation
Browse R Packages
We want your feedback!
Note that we can't provide technical support on individual packages. You should contact the package authors for that.
Embedding an R snippet on your website
Add the following code to your website.
For more information on customizing the embed code, read Embedding Snippets.